如何使用webscraper爬取图片并下载
1、webscraper插件地址https://pan.baidu.com/s/1EK_V4k57pjfO6GLr8DpGdw
下载完成后安装在谷歌浏览器上
2、打开我们需要爬虫的网址(这里我们拿新浪图片为例子)我们按下F12打开开发者工具,选择webscraper选项
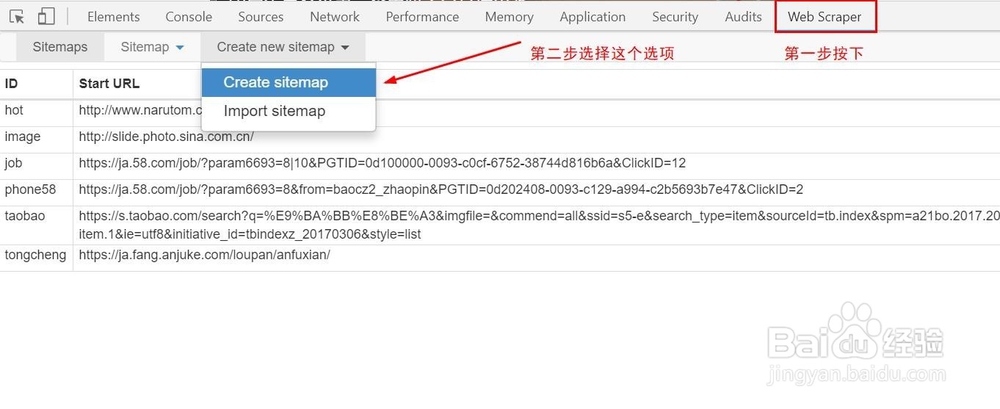
3、我们先创建一个项目,点击Create new sitemap->Create sitemap选项
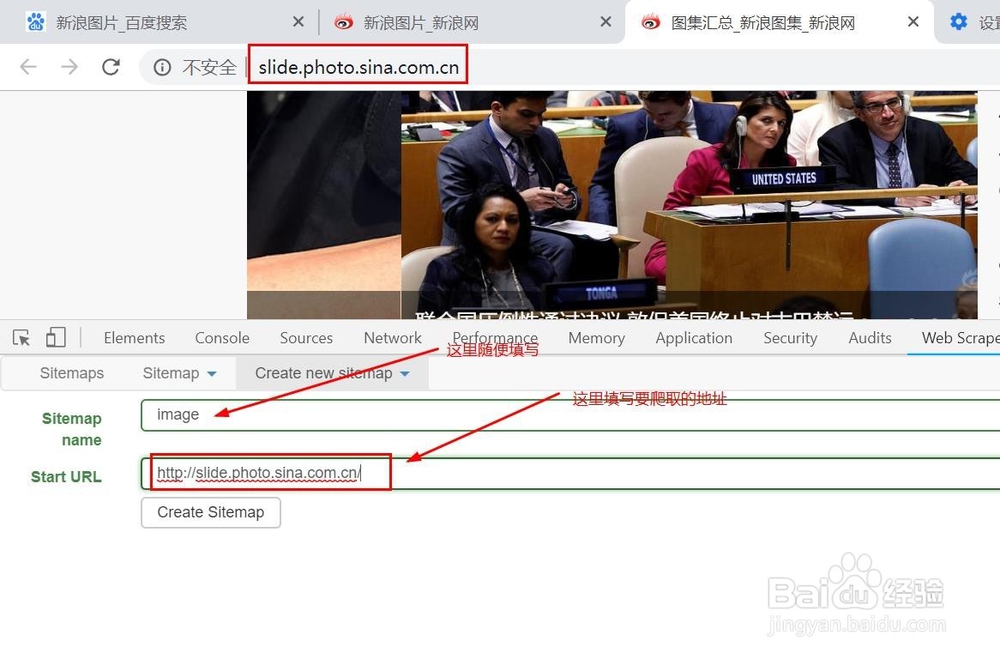
4、上面点击完之后会出现这样的界面,Sitemap name随便取个名字,我这里就填image,而Start URL里面填写需要爬取的地址,也就是我们新浪图片的网址,我们复制浏览器地址栏里面的地址,填写完之后我们单击按钮Create Sitemap
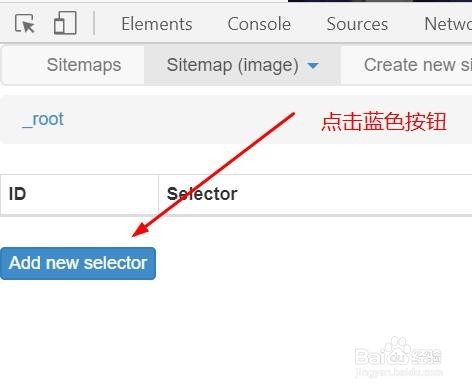
5、上面步骤执行完后会出现一个蓝色按钮,点击它一下
6、这个时候,id随便取一个名称,我这里取img,type选择Image类型,然后点击select按钮
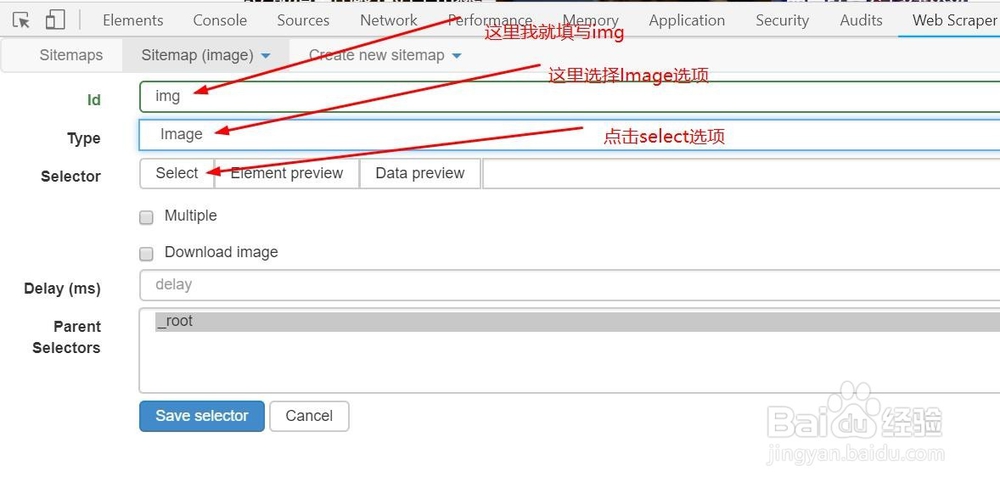
7、点击完select按钮,开发者工具会出现一个框,当出现这个框时,再将鼠标移动到图片区域,当绿色区域覆盖图片的时候,我们就点击一下
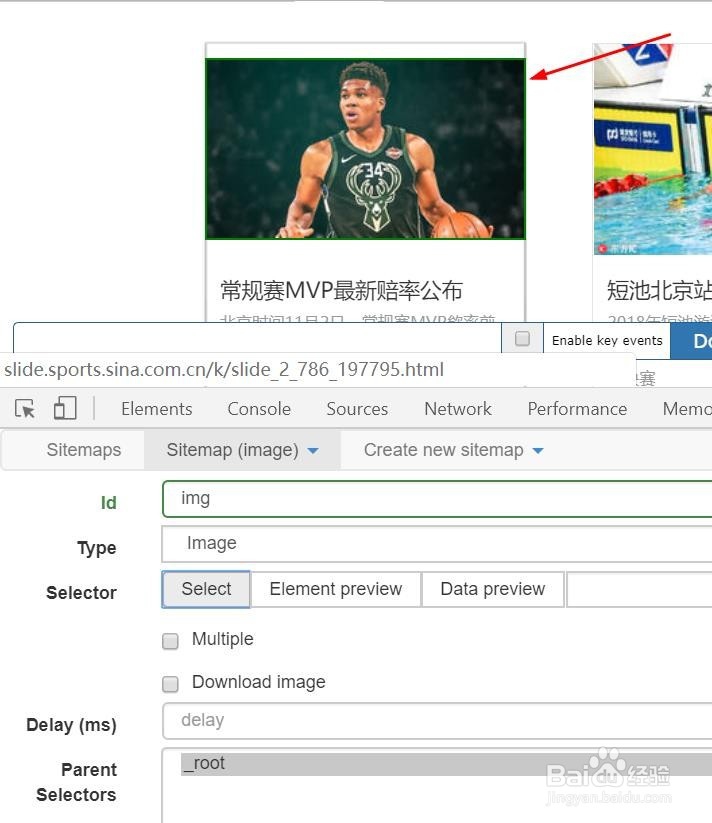
8、然后再点击第二个图片,当点完第二个图片,所有图片插件都会自动选择好
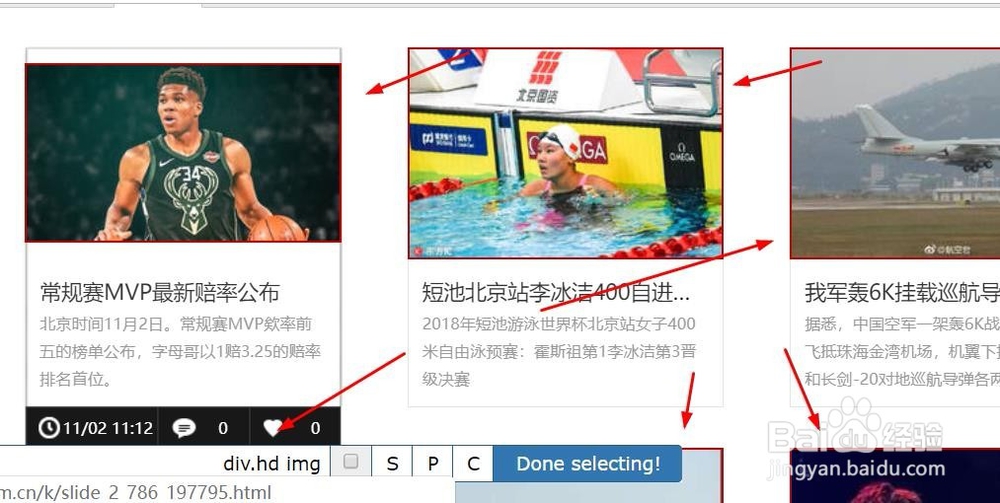
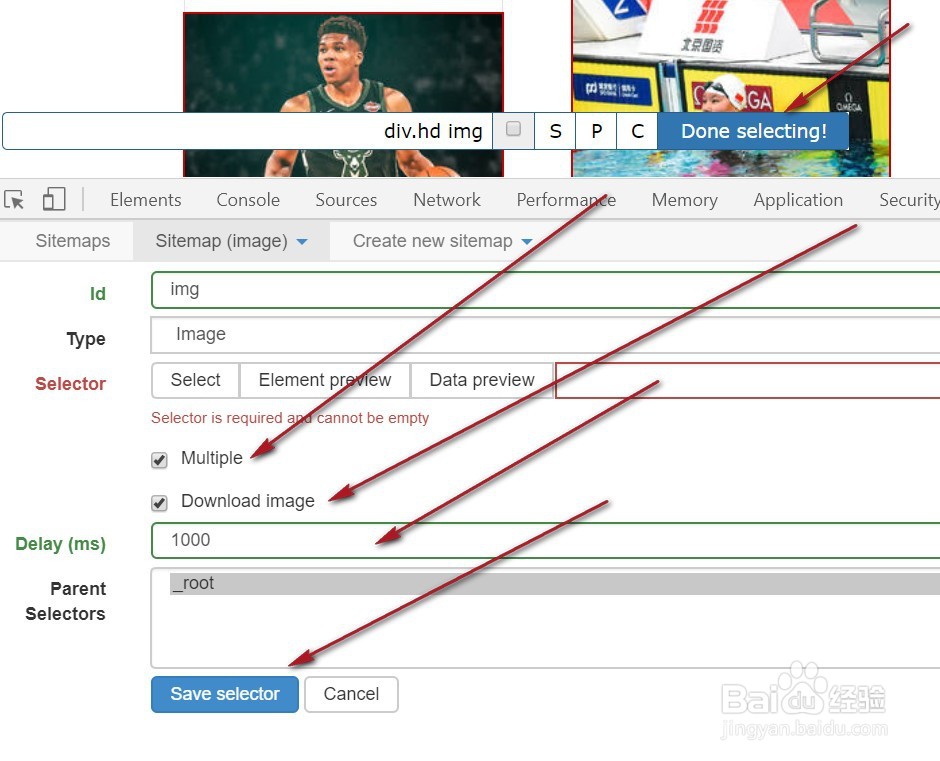
9、这个时候,就按下蓝色按钮Done selecting!,并且勾选Multiple(多条数据的意思),然后再勾选Download image(这个是下载图片的意思),Delay(延迟数,因为加载图片需要时间)那一栏填写毫秒数,网速慢的人可以多填一些,我这里就填写1000,最后点击蓝色按钮Save selector保存
10、现在就可以开始爬取了,点击上面的Create new sitemap->Scrape,然后点击蓝色按钮,就可以开始爬取了
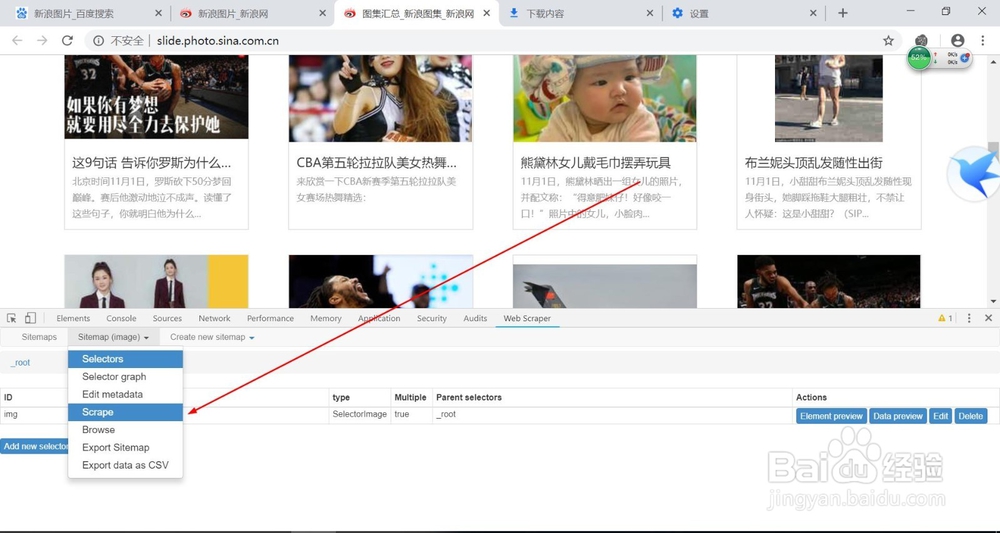
11、耐心等待图片下载,图片正在一张张地下载
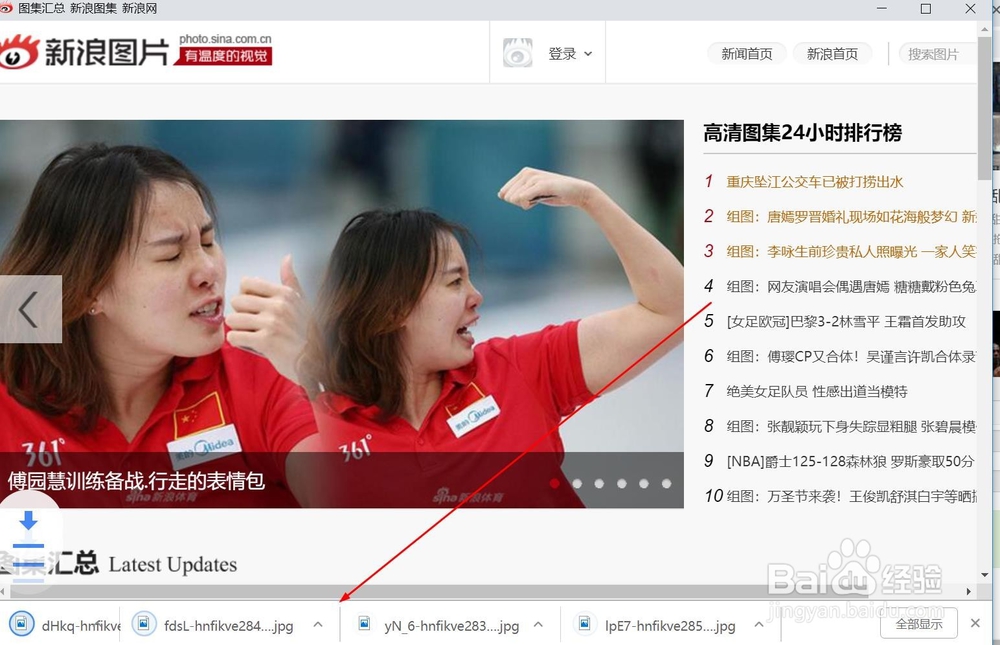
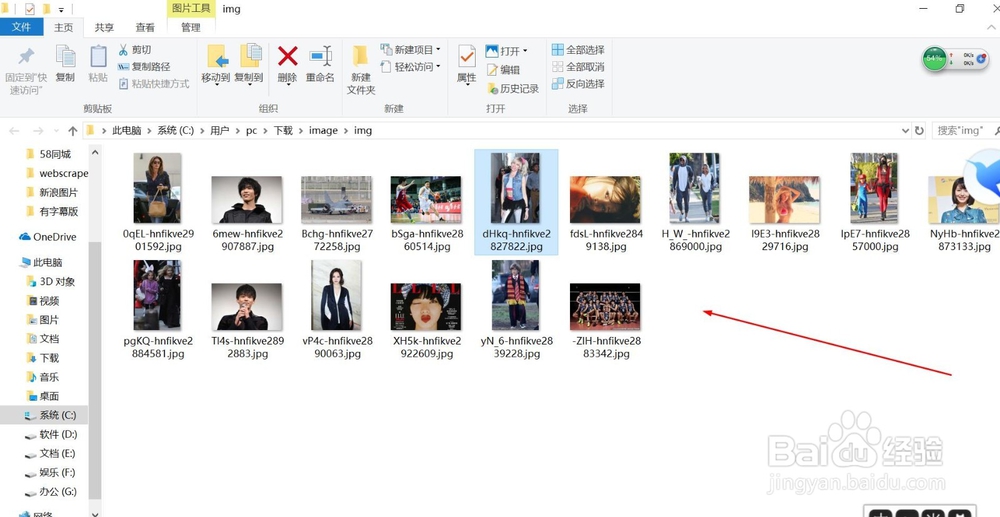
12、这时候我们再去下载路径看一下,图片都下载到下载路径里面,